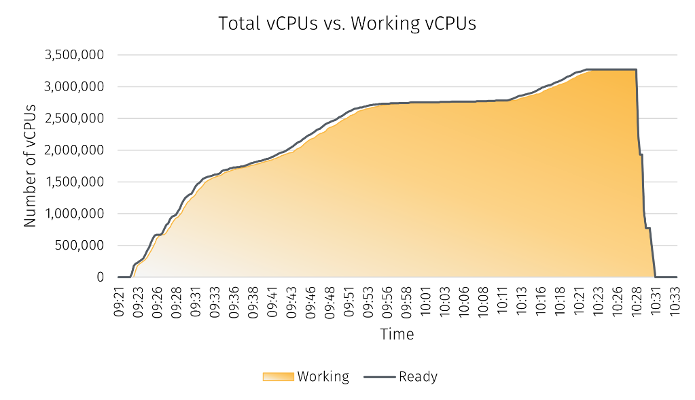
In this post, we’ll look at YellowDog’s performance and its operational characteristics that are important for FSI customers including: scheduling latency, throughput, and integration with AWS services. This is the second post in a series – in our previous post, we showed you how YellowDog can scale up to 3.2 million vCPUs on AWS in just under 33 minutes.
The challenge familiar to FSIs
Today, new financial regulatory requirements like FRTB (the Fundamental Review of the Trading Book), RWA (Risk Weighted Assets), and ESG (Environmental, Social, and Governance) have resulted in a significant increase (up to 10x) in computational demand, compelling FSI firms to find additional compute capacity.
Furthermore, FSI workloads often involve large numbers of short-running tasks, requiring a variation of HPC known as high throughput computing (HTC). It’s not uncommon to process more than 100 million tasks per day, with a substantial portion of these tasks taking less than two seconds to run. These characteristics can make many ‘normal’ job schedulers ill-suited for the task. But the ability to perform more computations, sooner, translates directly into improved quality of service and market competitiveness for an institution.
These factors are driving FSI firms to reimagine their computing grids and to explore cloud-based modernization pathways in pursuit of improved functionality and cost efficiency.
YellowDog is a leading cloud provisioning and job scheduling stack that enables customers across FSI to optimise their compute infrastructure and run complex workloads across multiple AWS regions, simultaneously. Today we’re evaluating the suitability of running YellowDog on AWS for FSI HTC workloads, specifically.