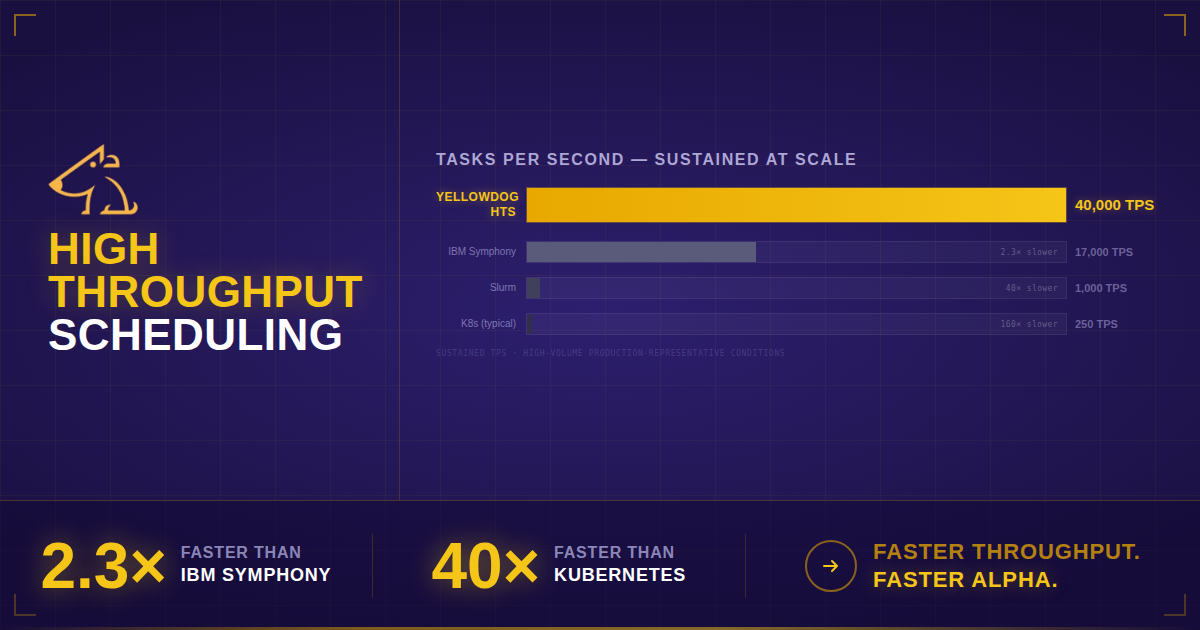
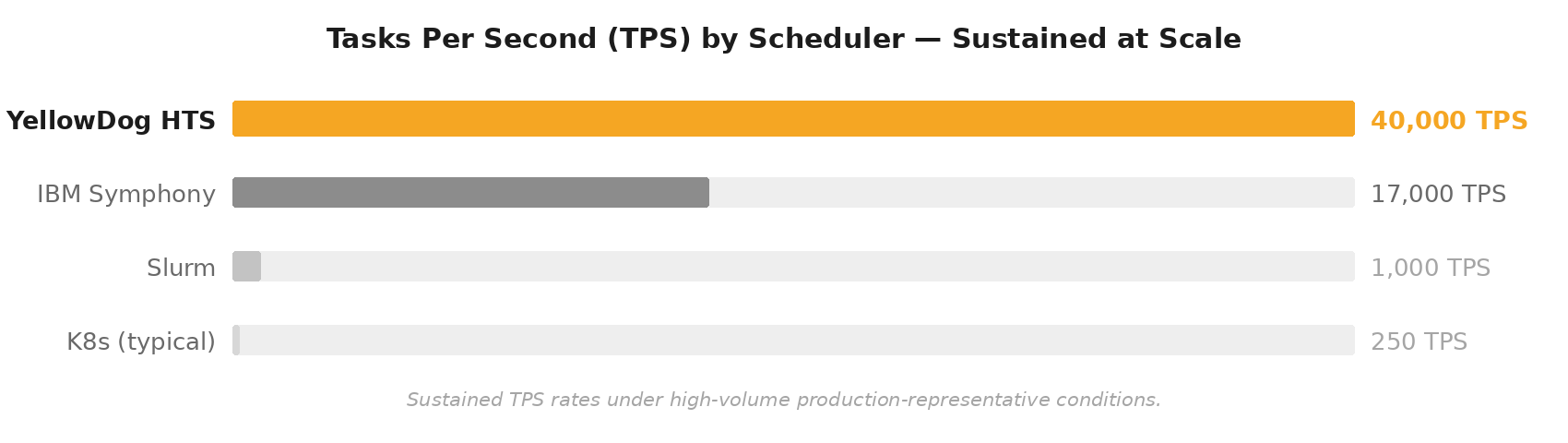
 At sustained 40,000 tasks per second, YellowDog HTS is:
At sustained 40,000 tasks per second, YellowDog HTS is:
- More than 2× faster than IBM Symphony
- 40× faster than Slurm
- More than 160× faster than a typical Kubernetes deployment
These differences translate into dramatic shortening of time to results.

IBM Symphony was designed for grid computing workloads where jobs run for extended periods and parallelism levels were far less evolved than they are today. At task volumes beyond 100 million tasks, the scheduler’s throughput ceiling becomes the dominant constraint.
Kubernetes was designed to orchestrate containerised microservices. While highly effective for long-running services, its scheduling model introduces latency that compounds as task counts rise. Workloads consisting of millions of short-lived jobs push Kubernetes well beyond its intended operating pattern.
Slurm is optimised for tightly coupled HPC workloads where a single scheduler manages a static cluster executing long batch jobs. That architecture works well for traditional, on-premises high-performance computing but is mismatched to bursty, massively parallel workloads such as Monte Carlo simulations and risk scenario grids.
YellowDog HTS was built specifically for these fine-grained, high-volume workloads, sustaining extremely high scheduling rates while keeping compute resources continuously utilised.
Agility: Throughput Speed As A Profit Engine For Financial Services
Everyday workloads for capital markets – FRTB, XVA, RWA, intraday VaR – routinely fan out into hundreds of millions of independent tasks. At that scale throughput speed becomes a critical factor that determines whether results arrive in time to drive trading activity or arrive too late to matter.
The table below shows what YellowDog HTS delivers for each of the four highest-volume workload types in capital markets and the concrete change it creates for the teams running them.
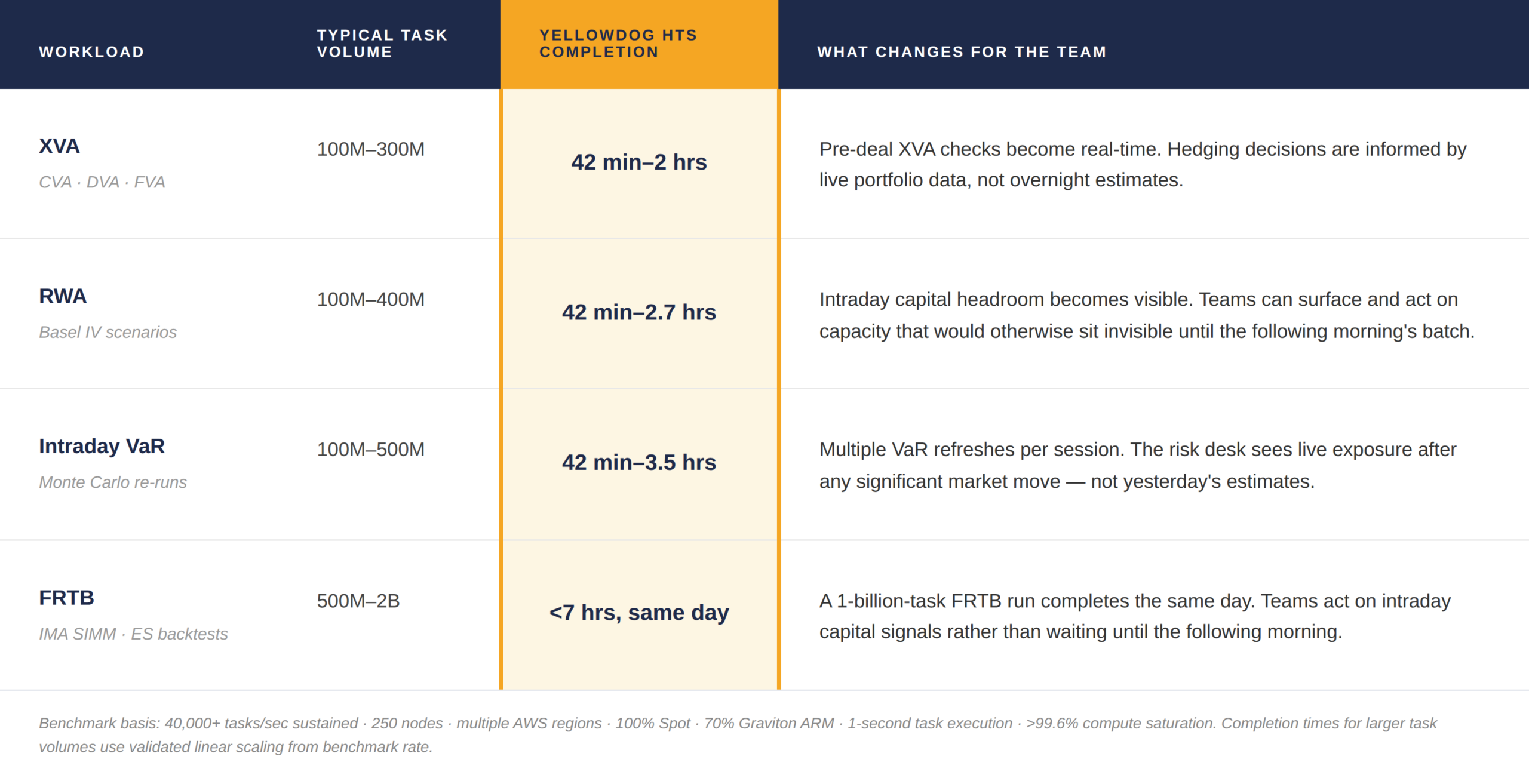
When workloads complete faster, teams gain the agility to iterate more quickly, test more scenarios, and act on updated risk signals within the trading window. Throughput becomes not just a performance metric but a driver of trading responsiveness and research velocity.
Cost: Spot, Graviton, And The Multi-Region Advantage.
Performance alone does not determine the value of large-scale compute. Cost efficiency is equally important.
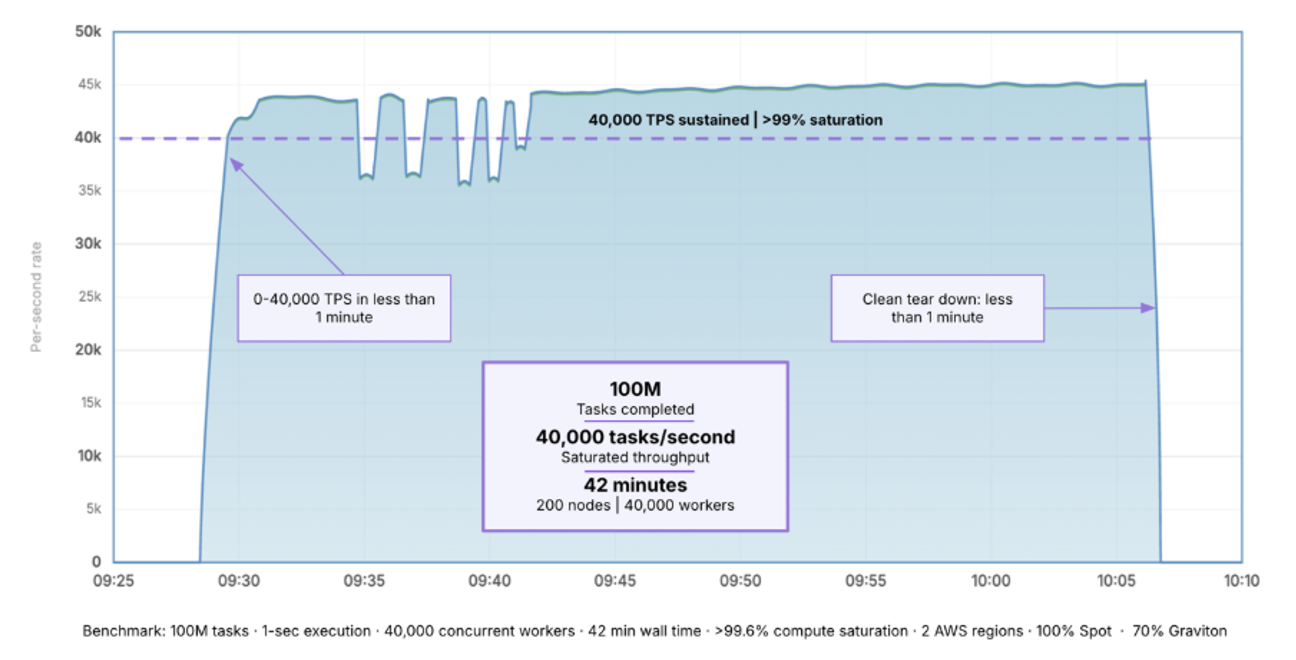
In the benchmark configuration, YellowDog orchestrated compute across multiple AWS regions, using 100% Spot capacity and 70% AWS Graviton instances.
Graviton processors provide strong price-performance characteristics and are typically 20–40% cheaper than comparable alternatives. It is also worth noting that IBM customers must pay an additional licensing fee to access Graviton. By giving teams the option to automatically select preferred instance types across regions, YellowDog ensures that workloads consistently run on the most cost-efficient cloud compute infrastructure available.
Equally important is utilisation. During the benchmark run, YellowDog maintained more than 99.6% worker saturation, meaning that compute resources remained productive from the first task to the last with almost no idle capacity.
Taken together, these capabilities produce a powerful economic model:
- Preferred hardware architectures such as Graviton
- Near-total Spot utilisation across regions
- Extremely high worker utilisation
The result is faster workloads delivered at significantly lower infrastructure cost combined with an HTS solution that massively compresses workload completion time.
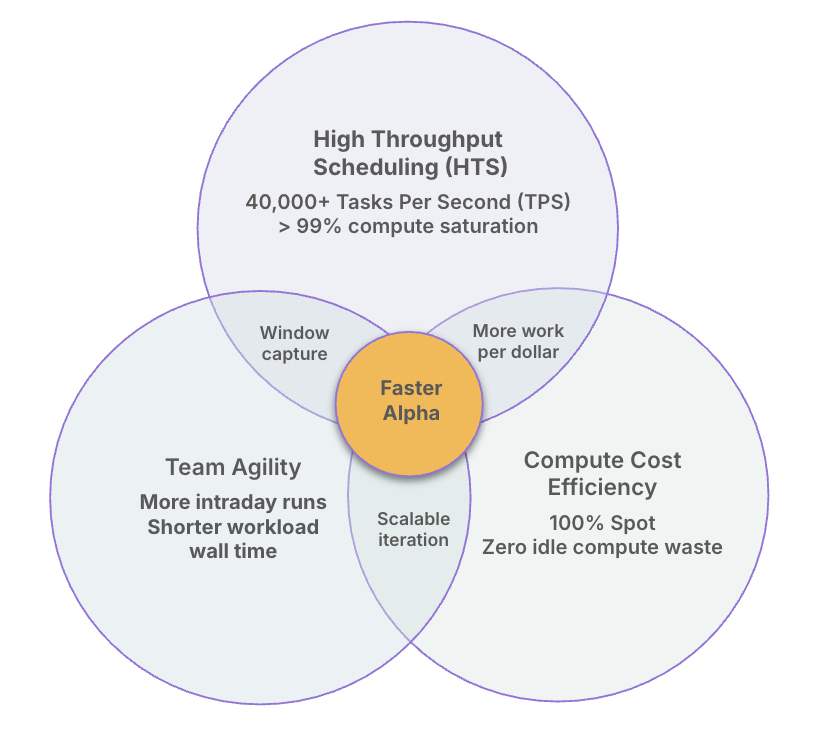
Three Forces. One Platform. One Outcome.
YellowDog HTS enables teams to generate alpha within the same trading window and refine strategies through rapid iteration before the opportunity closes. Scheduling throughput, compute economics, and team agility together determine how effectively workloads operate at scale.
Three forces drive this outcome:
- Throughput speed – how quickly tasks can be scheduled and executed
- Compute economics – the cost efficiency of running workloads at scale
- Agility – how rapidly teams can iterate on models and strategies
 YellowDog HTS drives faster alpha for financial services
YellowDog HTS drives faster alpha for financial services
Throughput without cost discipline produces fast results at unsustainable expense. Cheap compute without high utilisation leads to idle spend and unpredictable runtimes. Agility without either simply shifts the constraint elsewhere.
Only where all three overlap does durable advantage emerge.
- Throughput fast enough to capture opportunity.
- Economics efficient enough to justify scale.
- Infrastructure agile enough to iterate at market speed.
This is the position YellowDog occupies – unifying High Throughput Scheduling and intelligent multi-cloud compute orchestration in a single platform.
Scheduler Choice Makes A Difference
For financial services firms, the scheduler determines risk turnaround time, compute economics, and whether teams can act within market windows or after them. YellowDog is the only platform that addresses all three simultaneously.
Conventional grid schedulers cannot unlock full Spot utilisation across regions at this throughput. Compute orchestration alone cannot sustain tens of thousands of tasks per second with high worker saturation. YellowDog delivers both – in a single platform, without workload refactoring.
Next Steps: Benchmark YellowDog Against Your Own Workloads.
If your organisation is currently running high task workloads – or planning infrastructure to support extreme scale – you should benchmark YellowDog against your current environment. The numbers in this post are a starting point, but the results from a benchmark test will tell the true story.
YellowDog does not require disruptive refactoring. It can be introduced retrospectively or incrementally, allowing teams to test directly against real workloads immediately.
__
Read the original benchmark post: The Need for Speed: Throughput Defines The Fastest Time To Results
Contact us here to discuss your workload requirements: